Our paper on scalable, nuanced detection of phrase boundary credences from music tempo and/or loudness, and its application to a comparative analysis of Mazurka interpretations, is now available on Music & Science and is part of the collection on Explaining music with AI: Advancing the scientific understanding of music through computation guest edited by David Meredith, Anja Volk & Tom Collins.
Why study phrasing? Phrasing in performed music, analogous to making phrases and sentences in speech, provides a trace of a performer’s unique way of organising music material into coherent segments. Performers influence listeners’ perception of phrases by modulating tempo and loudness. Phrase boundaries are also closely tied to breathing, especially for wind players and vocalists. Being able to automatically extract phrase boundaries at scale allows us to study diversity in musical interpretations.
The method described in this Music & Science article is the latest in a series of papers on extracting phrase boundaries beginning with dynamic programming (Ching-Hua Chuan & Chew ISMIR 2007) and maximum a priori estimation (Dan Stowell & Chew 2013). The MazurkaBL dataset (Kosta, Bandtlow, Chew 2018), score-aligned loudness, beat, expressive markings for 2000 Chopin Mazurka recordings on which the method was tested was part of Katerina’s PhD.
Guichaoua, C., Lascabettes, P., & Chew, E. (2024). End-to-End Bayesian Segmentation and Similarity Assessment of Performed Music Tempo and Dynamics without Score Information. Music & Science, 7. doi.org/10.1177/20592043241233411
End-to-End Bayesian Segmentation and Similarity Assessment of Performed Music Tempo and Dynamics without Score Information
Corentin Guichaoua, Paul Lascabettes, Elaine Chew
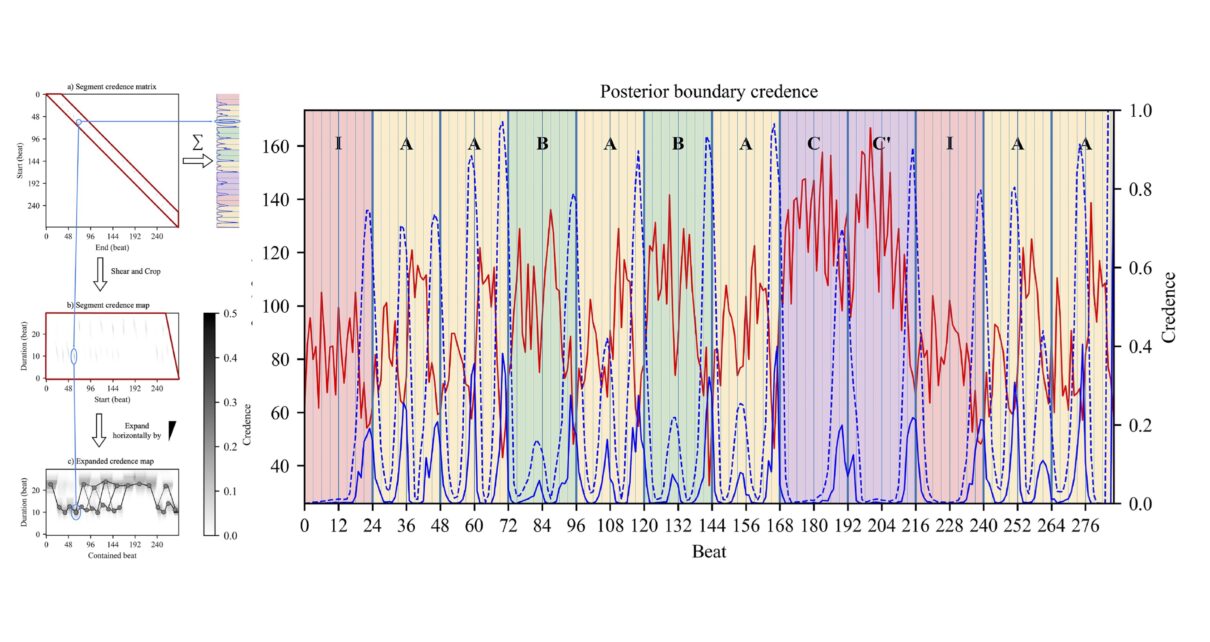
Abstract: Segmenting continuous sensory input into coherent segments and subsegments is an important part of perception. Music is no exception. By shaping the acoustic properties of music during performance, musicians can strongly influence the perceived segmentation. Two main techniques musicians employ are the modulation of tempo and dynamics. Such variations carry important information for segmentation and lend themselves well to numerical analysis methods. In this article, based on tempo or loudness modulations alone, we propose a novel end-to-end Bayesian framework using dynamic programming to retrieve a musician’s expressed segmentation. The method computes the credence of all possible segmentations of the recorded performance. The output is summarized in two forms: as a beat-by-beat profile revealing the posterior credence of plausible boundaries, and as expanded credence segment maps, a novel representation that converts readily to a segmentation lattice but retains information about the posterior uncertainty on the exact position of segments’ endpoints. To compare any two segmentation profiles, we introduce a method based on unbalanced optimal transport. Experimental results on the MazurkaBL dataset show that despite the drastic dimension reduction from the input data, the segmentation recovery is sufficient for deriving musical insights from comparative examination of recorded performances. This Bayesian segmentation method thus offers an alternative to binary boundary detection and finds multiple hypotheses fitting information from recorded music performances.
Code and data availability: Code for performing the probabilistic segmentation and its visualization is available at github.com/erc-cosmos/probabilistic-segmentation. The MazurkaBL data set is available at github.com/katkost/MazurkaBL.